
L'intelligence artificielle des textes
Entre Septembre 2019 et Juin 2021, le projet "L'intelligence artificielle des textes" a vu une collaboration étroite entre le DHLab de la MSI et le laboratoire BCL – Bases, Corpus, Langage. Cette collaboration a permis de développer de nouvelles méthodes d'analyse des textes, dans le cadre de l'apprentissage profond.
En particulier, des techniques innovantes d'inspection des couches cachées d'un réseau de neurones (feed-forward, convolutionnel ou récurrent) entraîné pour classifier, ont été mises au point. L'ensemble de ces techniques, que nous appelons Weighted Deconvolution Saliency (WTDS), permet de détecter, dans un paragraphe de texte d'un corpus, les passages clef utilisés par l'intelligence artificielle pour attribuer le paragraphe à une classe (à savoir à un auteur, à un domaine ou à un sentiment).
Les innovations les plus importantes sont liées aux points suivants :
- l'extraction de motifs via WTDS prend en compte le contexte. Par exemple, un même mot n'aura pas la même
importance selon sa position dans la phrase ; - elle détecte les impulsions de chaque
motif vers les différentes classes (voir Figure 1) ; - elle n'a pas des couts de calcul prohibitifs liés à des étapes de randomisation (comme il est le cas pour LIME où SHAP, par exemple).
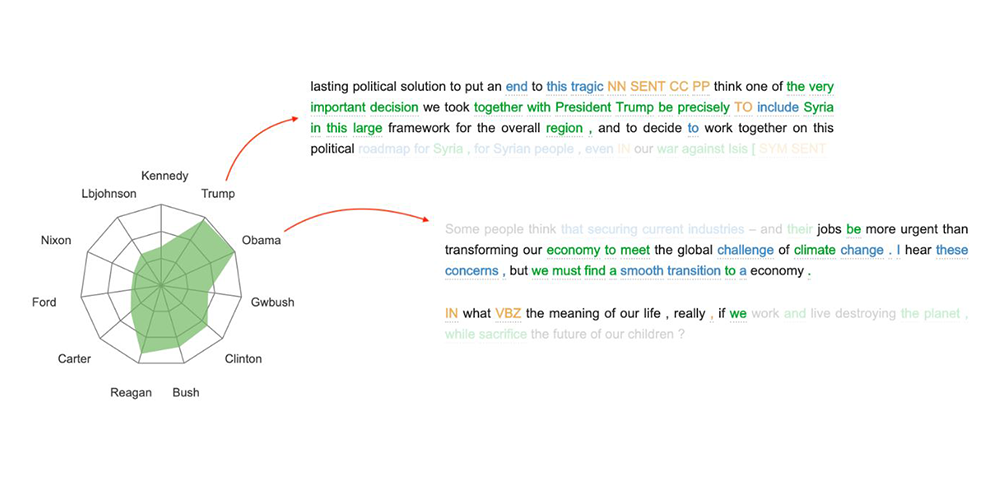
Publications :
L'ensemble des travaux réalisés dans le projet a fait l'objet de plusieurs publications incluant un chapitre d'ouvrage (1), une conférence (2) et un preprint en phase de soumission (3). WTDS a été mis en œuvre et déployé au sein du logiciel d’analyse de données textuelles ⟨Hyperbase⟩. D’autres publications récentes, réalisées à BCL, exploitent WTDS.
(2). Laurent Vanni, Marco Corneli, Dominique Longrée, Damon Mayaffre, Frédéric Precioso. Hyperdeep : deep learning descriptif pour l'analyse de données textuelles. JADT 2020 - 15èmes Journées Internationales d'Analyse statistique des Données Textuelles, Jun 2020, Toulouse, France. ⟨hal-02926880⟩
(3). Laurent Vanni, Marco Corneli, Damon Mayaffre, Frédéric Precioso. From text saliency to linguistic objects: learning linguistic interpretable markers with a multi-channels convolutional architecture. 2021. ⟨hal-03142170⟩
Participants au projet :
Camille Bouzereau (Doctorante, Laboratoire Bases, Corpus et Langage ), Magali Guaresi (Post-Doc, Université Libre de Bruxelles Post-Doctoral fellow), Dominique Longrée (Professeur, Université de Liège), Damon MAYAFFRE, (CR, CNRS), Céline Poudat (MCF, Bases, Corpus et Langage ), Frédéric Précioso (Professeur, Laboratoire I3S), Laurent Vanni, (IR, CNRS), Marco Corneli (Data Scientist, MSI).